A Typical Cluster
Describing a "typical cluster" is a bit misleading, as the configuration really depends a lot on your budget, and exactly what the cluster will be used for. Will the cluster be used for a general audience with varied needs or a single purpose? What's your security posture? Do you need to protect sensitive data from the outside world, or maybe from other cluster users? How much resiliency to you need? Can your cluster be down for an hour? A day? A week? How important is speed? Do you need a high-speed interconnect? High-speed data access? Backups? Scratch space?
Before we get into all these issues, here's what a "typical cluster" looks like:
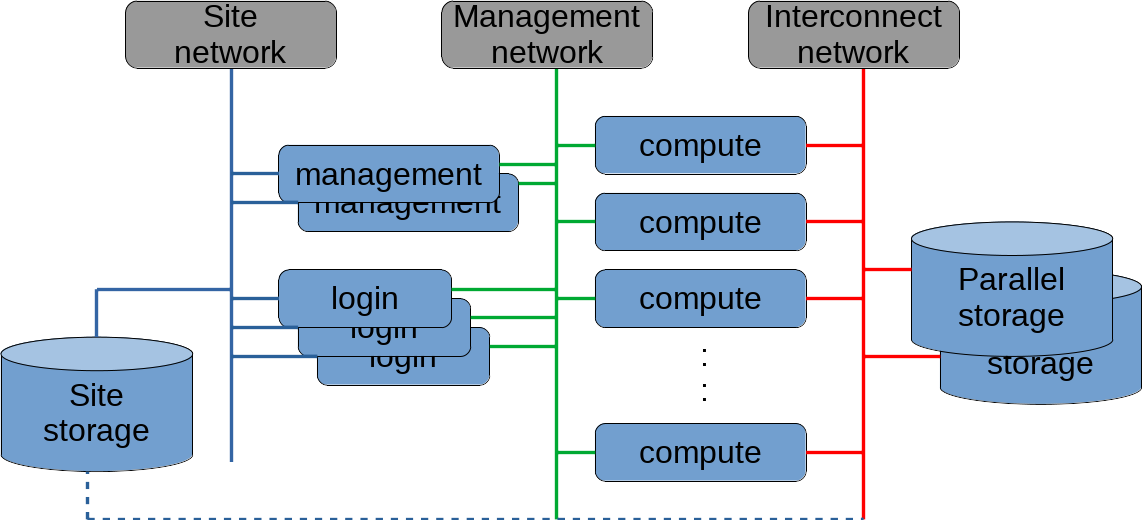
What this image shows is a fairly standard cluster. Before we go into depth on the details, let's back up and discuss clusters in terms of scientific computing.
When we talk about scientific computing, we're referencing a very broad field of topics, including Genomics, Computational Fluid Dynamics, Astrophysics, Molecular Dynamics, and many others. As we strive to advance our knowledge in these fields, we also need to push our computational abilities. As the old adage goes, all the easy research has already been done.
When we hit the limit of the computational abilities of our workstation, we can buy a newer, faster workstation. When we hit the limits of the best workstations of the day, we typically need to turn to computational facilities at the institutional level. Sometimes these are specilized computers (think of the mainframe computers of days gone past), but more often than not, those facilities are clusters. By joining many computers together through specialized hardware and software, we're able to far exceed the abilities of any single computer. Clusters allow us to solve problems that may have taken weeks or years on a single machine in a fraction of the time.
This type of computational resource is what is illustrated in the diagram above. A typical cluster usually has one or management nodes that are used to control and monitor the cluster, one or more login nodes where users can log in, compile code, and submit jobs, and a number of compute nodes where the jobs actually run. A job manager or scheduler determines which jobs run on which compute nodes, and when they run. There may also be high-speed parallel storage available, in addition to any normal (typically slower) site storage.
Networking
Networking is typically composed of three distinct networks: the local site network or Local Area Network is where users typically conduct the majority of their tasks. This may be exposed to the Internet, but is normally protected behind a firewall and restricted to people within the organization. This is depicted as the solid blue lines in the diagram above.
The management network is typcally an isolated network where the management node communicates with the compute nodes for scheduling and monitoring jobs, deploying software, and performing general management tasks on the compute nodes. This is typically commodity hardware that is not high-speed, but uses well known and tested network technology for maximum reliability. This network is depicted in the diagram above with solid green lines.
Most clusters include an interconnect network as well, for high-speed communications between the compute nodes. Often, there is also a high-speed parallel file system on this network. This network sometimes uses high-speed Ethernet to connect the compute nodes, but more often uses InfiniBand or a specialized custom-built networking technology to maximize the throughput. For jobs that run across multiple nodes, the interconnect usually determines the speed of the job more than any other hardware component.
Storage
Storage is probably the area with the most variation in clusters. Users typically keep their code and data on commodity storage that is accessible outside the cluster. If your users are running code that is data-intensive (requires a lot of I/O operations), you will usually have some kind of high-speed storage available for your cluster.
If you look at the cluster diagram above, you'll see a dashed line from site storage across to the interconnect network. If your security requirements are low, this can be a convenient configuration. Users can run their jobs with the same storage access they use outside the cluster. For I/O intensive jobs, however, this can put quite a strain on your site storage servers. One alternative is to read data from site storage and use a parallel file system as scratch space for computation, and then write the results back to site storage.
If your security requirements are a bit higher, your site storage may not be accessible at all from the cluster compute nodes. In this case, a user will typically stage or copy their data to the parallel file system before their job runs, do their computation on the parallel storage, and then stage the results back to site storage. Staging data is still a difficult issue to deal with. The data staging typically takes place at the beginning of a job, but that leaves compute resources idle while the data is being moved. There are methods to minimize the idle time for the compute nodes, but there still isn't a standard way of dealing with this problem.
Software
If your cluster is built for a single purpose or a single application domain, maintaining your software should be relatively easy. You will have a small number of applications that you can optimize for your environment, and optimize your cluster for those applications. If this is the environment you're working in, you will probably end up with a number of licensed software products. Managing licenses in a clustered environment is often a significant challenge.
For any facility that supports research, a large number of your tools will be Open Source, and you will need to download and build the software yourself. It's a constant task to keep software updated and optimized, and typically people are always asking for new software packages to be installed. Contrarily, some of your users will need to retain old versions of software because their code hasn't been updated to use newer libraries, or because they need to keep old versions for reproducibility. Familiarize yourself with modules to retain your sanity. There's a brief introduction to modules here